Telstra Data & AI
Delivered multiple applied machine learning and AI initiatives spanning fraud detection, LLM optimisation, MLOps infrastructure, and responsible AI, supporting enterprise-scale data platforms and ethical AI governance across Telstra’s Data & AI organisation.
QAI – Intelligent Call Transcript Triage
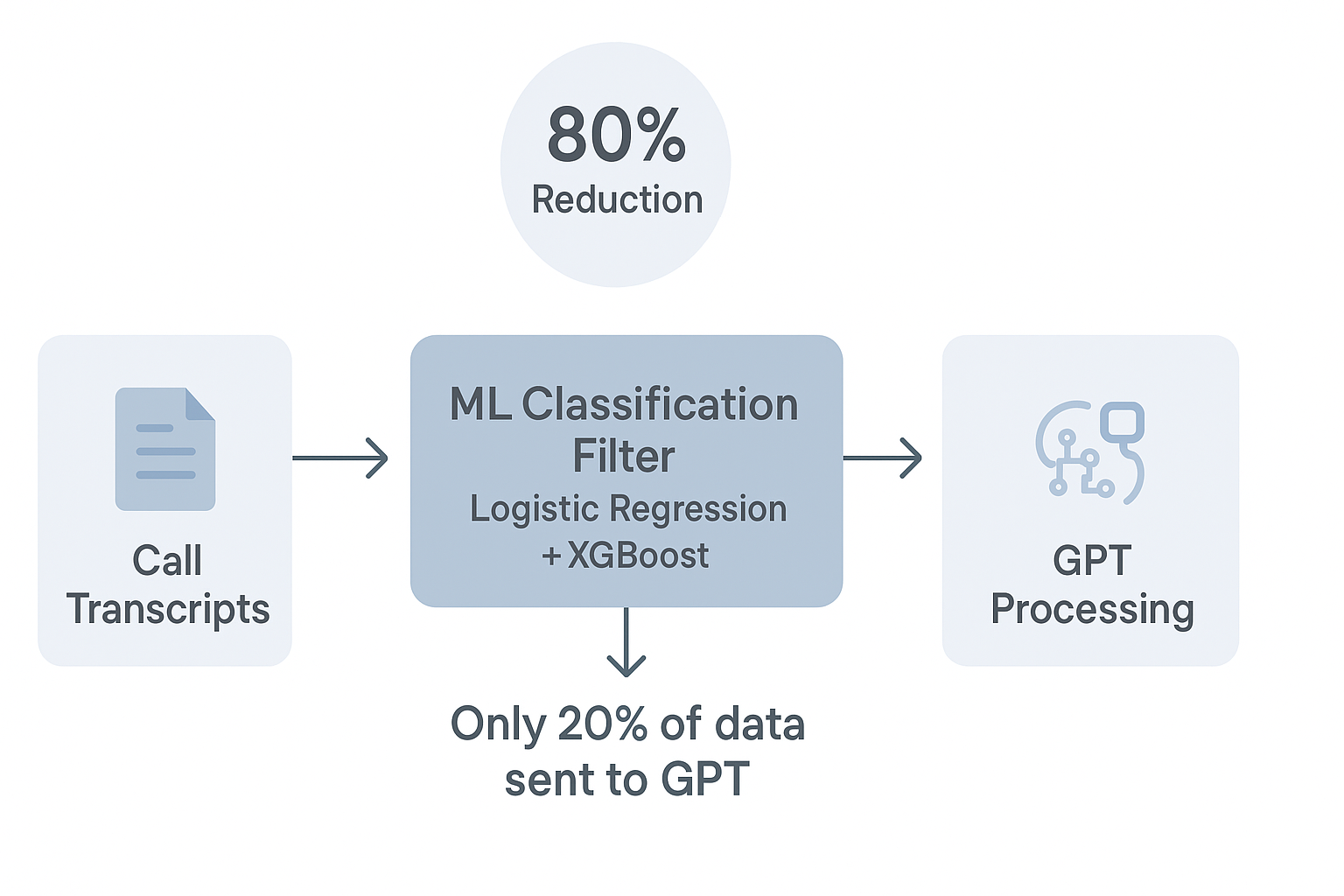
Built a hybrid XGBoost + Logistic Regression pipeline to triage call transcripts before GPT processing.
Reduced LLM workload by ~80%, cutting processing time from 8 hours to under 2.
Processed 1.5M+ transcripts across three compliance categories (DL, PA, AU).
Achieved 0.94–0.98 recall by addressing class imbalance (<5% positives) with threshold tuning and undersampling.
Implemented ensemble voting strategy to optimise positive vs negative classification.
Applied TF-IDF, lemmatisation, n-grams, and extensive hyperparameter tuning (GridSearchCV, RandomisedSearchCV).
Improved GPT output accuracy through refined prompt/query design.
Tools: Python, Scikit-learn, XGBoost, TF-IDF, Pandas, NumPy.
Impact: Faster compliance triage, reduced compute costs, scalable LLM preprocessing workflow.
Fraud Detection – Call Transcript Classification


Built an end-to-end ML pipeline to detect fraudulent behaviour in call transcripts.
Improved fraud identification accuracy and reduced manual review effort by 60%.
Processed large text datasets with cleaning, balancing, and noise handling.
Trained multiple classifiers (Logistic Regression, RandomForest, XGBoost) with hyperparameter tuning.
Solved overfitting and memory constraints using feature selection and stratified sampling.
Enhanced interpretability using RAKE and ELI5 to explain model outputs.
Delivered visual dashboards and analysis via Matplotlib, Seaborn, and ipywidgets.
Tools: Python, Pandas, NumPy, Scikit-learn, SpaCy, RAKE, ELI5.
Impact: Automated scalable fraud detection with transparent insights.
MLOps & Orchestrator – Data Platform Engineering
Built a scalable MLOps platform with CI/CD, monitoring, and automated model deployment.
Developed orchestrator workflows using Airflow + Docker + Postgres on Ubuntu/WSL.
Created Quicksight dashboards for ingestion monitoring and feature drift detection.
Enhanced Python validation scripts for dynamic anomaly detection in CSV inputs.
Built New Relic observability dashboards for Quantium–Telstra data models.
Standardised DAG execution with Function App automation aligned to Azure DevOps best practices.
Impact: Improved reliability of ML pipelines, reduced data incidents, and streamlined deployment.
Tools: Airflow, Docker, Postgres, Quicksight, New Relic, Python.
Risk & Ethics – AI Risk Register (AIROC)
Led development of Telstra’s organisation-wide AI risk tracking system.
Designed and built an automated Power Apps + Power Automate workflow to replace manual Excel processes.
Migrated and cleansed legacy risk data, ensuring consistency and traceability.
Documented governance procedures and delivered handover training to new graduates.
Supported adoption across multiple business units and aligned the register with Telstra’s Responsible AI Framework.
Tools: Power Apps, Power Automate, Python (Pandas, NumPy, Matplotlib), VS Code.
Impact: Improved transparency, consistency, and oversight of ethical and operational AI risks.


Biostatistics
HTIN – Applied Healthcare Data Science
Built ML models for clinical prediction, biomedical signal analysis, medical imaging, and drug discovery.
Applied regression, clustering, PCA, RNNs, Transformers, and LDA topic modelling.
Worked with real health datasets across time-series, text, and images.
Gained experience in feature engineering, model interpretation, and evaluation metrics used in healthcare analytics.
Tools: Python, scikit-learn, PyTorch, DeepReg, Opacus.
Outcomes: strengthened skills in supervised/unsupervised learning, clinical NLP, and differential privacy for sensitive data.
PSI – Principles of Statistical Inference
Studied likelihood theory, Bayesian inference, and hypothesis testing.
Applied MLE, Wald/score tests, and bootstrap methods.
Built skills in interpreting significance, Type I/II errors, and model uncertainty.
Tools: R, Python.
DMC – Data Management and Computing
Gained skills in data cleaning, transformation, merging, and database design.
Applied reproducible programming, scripting, and workflow automation.
Created quality visualisations and performed data integrity checks.
Tools: R, Python, Excel.

Machine Learning Project – Mercari Price Suggestion Challenge (UNSW)
Built a machine learning model to predict product prices for 1.4M+ Mercari listings, addressing high variability across brands, categories, and conditions.
Cleaned and processed large-scale structured and unstructured text data (missing values, encoding, tokenisation, stop-word removal, stemming).
Extracted text features using TF-IDF and Doc2Vec, converting millions of item descriptions into numeric vectors.
Trained and compared regression models (Ridge, Lasso, SVR) with GridSearchCV and cross-validation for hyperparameter tuning.
Applied log transformation and dimensionality reduction to stabilise variance and reduce feature redundancy.
Achieved best performance using Ridge Regression + TF-IDF, scoring 0.477 RMSLE (top quartile of Kaggle leaderboard).
Ensured reproducibility with structured experimentation, documentation, and feature importance analysis.
Tools: Python, scikit-learn, Gensim, Pandas, NumPy, Matplotlib, Google Colab.
Impact: Delivered an interpretable, scalable pricing model demonstrating advanced NLP feature engineering and large-dataset ML workflows.